1.0 The Architecture Of SQLite
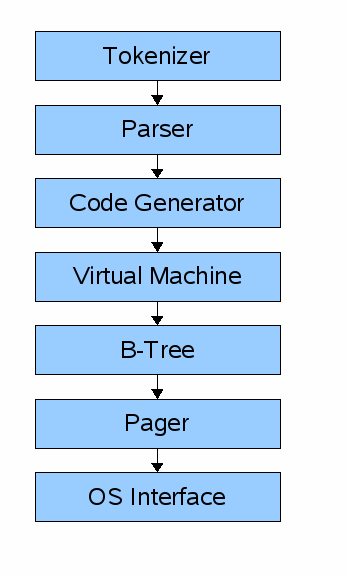
An understanding of SQLite is a prerequisite for understanding ZIPVFS. The diagram at the right provides a high-level overview of the internal organization of SQLite. The Tokenizer, Parser, and Code Generator components are used to process SQL statements and convert them into executable programs in a virtual machine language. The Virtual Machine module is responsible for running the SQL statement byte code. The B-Tree module organizes a database file into multiple key/value stores with ordered keys and logarithmic performance. The Pager module is responsible for loading pages of the database file into memory, for implementing and controlling transactions, and for creating and maintaining the journal files that prevent database corruption following a crash or power failure. The OS Interface is a thin abstraction that provides a common set of routines for adapting SQLite to run on different operating systems.
The components that interact with ZIPVFS are the bottom two: the Pager and the OS Interface. Hence, we will provide additional details on those two components.
The OS Interface is really an abstract class called "sqlite3_vfs" that can be subclassed to provide an operating system interface for the various machines upon which SQLite runs. We call each subclass of sqlite3_vfs a "VFS" which is an acronym "Virtual File System". The VFS objects provide methods such as the following:
- Check for the existence of a file on disk.
- Delete a file.
- Open a connection to a file.
- Read or writes a specific number of bytes from a specified location within an open file.
- Truncate a file.
- Close a file connection.
- Return the size of a file in bytes.
- Flush buffered file content to the disk surface.
- Lock or unlock a range of bytes within a file.
And so forth. The SQLite core never invokes any operating-system interface calls itself. Instead, when SQLite needs to manipulate files (or take advantage of other operating system services) it invokes methods in a VFS object and that VFS object translates the request into system calls appropriate for the underlying operating system.
SQLite allows multiple VFSes to be active at once. Each SQLite database connection can have a different VFS if desired. New VFSes can be added to SQLite at runtime simply by passing a pointer to the new VFS object to SQLite. Each VFS has a name. When opening a new SQLite database connection using the sqlite3_open_v2() interface, the 4th argument is the name of the VFS that connection should use. Though there may be multiple VFSes associated with SQLite, exactly one VFS will be the "default VFS". If no VFS is specified in the sqlite3_open_v2() call - if the 4th parameter to sqlite3_open_v2() is NULL - then the default VFS is used. This is the common case.
In the standard builds of SQLite for posix and windows systems, the default VFS is a VFS that is appropriate for that operating system. Sometime extra VFSes are included as well. For example, for posix builds, the default VFS is called "unix" and uses posix advisory locking. But there are other built-in VFSes such as "unix-dotfile" which uses dot-file locking and "unix-nolock" which no-ops all the locking primitives. The key point here is that multiple VFS objects can exist and be in use within SQLite at the same time.
The Pager module in SQLite is responsible for loading specific "pages" of a database file into memory when requested by higher-level modules in the stack, and for transaction processing in SQLite. For example, if the B-Tree module needs to see the content of the 17th page of a database file, it asks the Pager and the Pager either looks up that page in its internal cache, or reads it from disk into its internal cache, then returns a pointer to the page content to the B-Tree module.
The Pager is also responsible for transactions. Higher level layers tell the Pager to start a transaction, commit a transaction, or rollback a transaction, and the Pager takes care of the details. The Pager also makes sure the writes are ordered to disk in such a way that no data is lost in a crash or power failure. And the Pager automatically handles recovery processing upon restart after a crash or power failure.
The Pager is a object, like the VFS. There is a separate Pager object for
each open database file. But, unlike the VFS, the Pager object never needs
to be subclassed. Every time a new database connection is opened using
sqlite3_open() or sqlite3_open_v2(), or every time a new database is added
to an existing database connection using the ATTACH command, a new Pager
object is created to manage that database file. One of the parameters used
when instantiating the Pager object is a pointer to the VFS object
that the Pager should use to communicate with the operating system.
2.0 The Architecture Of ZIPVFS
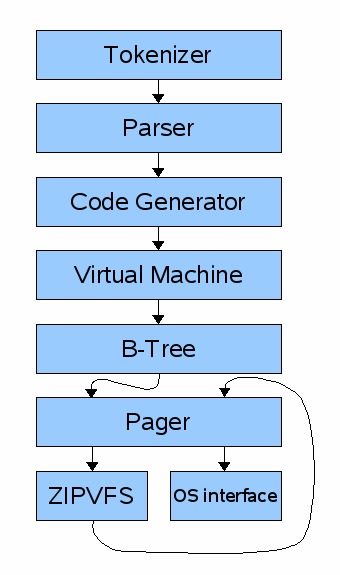
The ZIPVFS extension functions as a new VFS object. From the point of view of higher layers in the SQLite stack, the ZIPVFS object works like any other VFS object in that it handles all the disk I/O. But internally, the ZIPVFS layer compresses data as it is written and uncompresses the data as it is read. Hence higher layers see fully uncompressed data in the usual SQLite database format while compressed content is stored on disk.
Unlike native VFSes, the ZIPVFS does not talk directly to the underlying operating system. If it did, that would requires a different ZIPVFS for each operating system. Instead, the ZIPVFS relays raw I/O operations down to the native VFS object. So the ZIPVFS operates as a layer or "shim" that is inserted in between the standard Pager and the native VFS for the system.
But there is an additional wrinkle. The defensive measures that the Pager object takes to prevent database corruption following a crash or power loss assume that databases pages are aligned with disk sectors, which is true for most VFSes. But in the ZIPVFS, because of compression, the pages are of differing sizes and are hence no longer sector aligned. This means that the defensive measures taken by the Pager that sits above the ZIPVFS module are ineffective at preventing database corruption following a power loss. The ZIPVFS has to allocate a second Pager object to sit between it and the native VFS. Because this second Pager object sees the compressed content, which is now sized as it will be stored on disk, the second pager is able to effectively guard against damage from power loss.
The diagram to the right outlines the arrangement when ZIPVFS is in use. The B-Tree layer and everything above it are unchanged. The B-Tree module talks to the first Pager object. The first Pager uses the ZIPVFS module as if it were a direct interface to the underlying operating system. But ZIPVFS does not talk directly to the OS. Instead it allocates a second Pager object which in turn talks to the underlying OS through the native VFS.
2.1 Multiple Journal Files
There are two Pager objects in the module stack for SQLite when ZIPVFS is in use. The upper Pager, the one that sits in between the B-Tree and the ZIPVFS, handles explicit transactions using the BEGIN, COMMIT, ROLLBACK, and SAVEPOINT commands of the SQL language. In a normal SQLite configuration, the upper Pager would be the only Pager and so it would also handle protection from power loss damage using a journal file located in the same directory as the database file. But with ZIPVFS, the upper pager is not effective at this task. So the ZIPVFS shunts the journal file created by the upper pager into a temporary directory. The lower Pager that sits in between the ZIPVFS module and the native VFS is responsible for ensuring database consistency across power failures and crashes. The lower Pager has its own journal for this purpose. The journal file that resided in the same directory as the original database file is the journal that comes from the lower Pager.
Because there are two Pager objects in the stack when ZIPVFS is being used, there are two journal files, one for each Pager. This is not as bad as it might sound. The journal file for the upper Pager is never synced to disk. So on an operating system with a good disk cache, it might never be written to disk at all. Developers can ensure that the upper pager is never synced to disk by running:
PRAGMA journal_mode=MEMORY;
The disadvantage to using journal_mode=MEMORY is that for a large transaction, the in-memory rollback journal might use up too much RAM. Starting with SQLite version 3.15, an alternative is to disable the journal of the upper Pager entirely using:
PRAGMA journal_mode=OFF;
With the journal_mode is OFF, less memory is used, but the following caveats apply:
- If a ROLLBACK command is executed to roll back a write-transaction, or if a write-transaction is rolled back for any other reason (an OR ROLLBACK constraint, for example), then all active SELECT statements that belong to the same database handle are aborted (fail with SQLITE_ABORT).
- If a "ROLLBACK TO" command is executed to roll back a savepoint, or if a constraint failure causes a statement transaction to be rolled back, all active SELECT statements belonging to the same database handle are aborted. Additionally, all attempts to COMMIT the transaction or execute any other SQL statement apart from ROLLBACK fail with SQLITE_ABORT until the outer transaction has been rolled back.
Using journal_mode=OFF with versions of SQLite earlier than 3.15 can lead to database corruption under some circumstances.
In a database connection that does not use ZIPVFS, setting the journal_mode to either MEMORY or OFF causes the database to go corrupt following crashes and power failures. But when ZIPVFS is in use, it is the lower Pager than provides protection from crashes and power failures, so the journal_mode of the upper Pager can be switched to MEMORY or OFF without risk of data loss due to a power loss or OS crash. On the other hand, switching the journal_mode to MEMORY or OFF either requires more memory or disables savepoint and statement rollback, respectively. An engineering tradeoff is required. The best journal_mode setting for the upper pager must be decided on a case by case basis.
2.2 Multiple Page Caches
Both Pager objects in the module stack may cache pages. The upper level Pager, which caches pages of uncompressed data, may be configured using the usual PRAGMA page_size and PRAGMA cache_size commands.
The page size used by the lower level Pager may be queried, but not updated, using the "PRAGMA zipvfs_block_size" command:
PRAGMA [database.]zipvfs_block_size
The only way to configure the page size used by the lower level page size is by specifying a uri parameter of the form "block_size=<pgsz>" when opening the database file, where <pgsz> is a power of 2 between 512 and 65536, inclusive. For example:
file:zipped.db?vfs=zlib&block_size=4096
Unlike the upper level Pager page-size or the page-size of a non-zipvfs SQLite database, the block size is not a persistent property of the database file. Unless the database is in wal mode (i.e. "PRAGMA zipvfs_journal_mode=wal" has been executed) then multiple clients may simultaneously use different block sizes. For wal mode databases, all clients must use the same block size. This is managed automatically, the second and subsequent clients to open the database always use the same block size as the first, regardless of any block_size uri parameter.
The size of the cache used by the lower level Pager may be queried or configured using the "PRAGMA zipvfs_cache_size" command:
PRAGMA [database.]zipvfs_cache_size PRAGMA [database.]zipvfs_cache_size = pages PRAGMA [database.]zipvfs_cache_size = -kibibytes
The start of each zipvfs database file contains a table used to locate the compressed version of each database page within the file. The table is slightly larger (say 200 bytes larger) than 8 bytes per page in the uncompressed database (the value returned by the PRAGMA page_count command). When possible, the lower level page cache should be configured so that it is large enough to cache this entire table. However, if memory is tight, it should be noted that a cache miss in the upper level Pager is more expensive than a cache miss at the lower level (as data has to be uncompressed as well as read from disk). Experimenting with a range of values to determine how memory should be divided between the upper and lower level caches for optimal performance is the best course of action in such cases.
Within read-only transactions on zipvfs databases that are not in wal mode,
the table at the start of the file is the only part of the file accessed via
the low-level page cache - other data is read directly from the file. Under
these circumstances, the lower level page cache never uses much more than 8
bytes of memory for each page in the database, regardless of the
zipvfs_cache_size setting.