1. Summary
The LSM embedded database software stores data in three distinct data structures:-
The shared-memory region. This may actually be allocated in either shared or heap memory, depending on whether LSM is running in multi (the default) or single process mode. Either way, the shared-memory region contains volatile data that is shared at run-time between database clients. Similar to the *-shm file used by SQLite in WAL mode.
As well as various fixed-size fields, the shared-memory region contains the 'in-memory tree'. The in-memory tree is an append-only red-black tree structure used to stage user data that has not yet flushed into the database file by the system. Under normal circumstances, the in-memory tree is not allowed to grow very large.
-
The log file. A circular log file that provides a persistent backup of the contents of the in-memory tree and any other data that has not yet been synced to disk. The log-file is not used for rollback (like an SQLite journal file) or to store data that is retrieved at runtime by database clients (like an SQLite WAL file). Its only purpose is to provide robustness.
-
The database file. A database file consists of an 8KB header and a body. The body contains zero or more "sorted runs" - arrays of key-value pairs sorted by key.
To query a database, the contents of the in-memory tree must be merged with the contents of each sorted run in the database file. Entries from newer sorted runs are favoured over old (for the purposes of merging, the in-memory tree contains the newest data).
When an application writes to the database, the new data is written to the in-memory tree. Once the in-memory tree has grown large enough, its contents are written into the database file as a new sorted run. To reduce the number of sorted runs in the database file, chronologically adjacent sorted runs may be merged together into a single run, either automatically or on demand.
2. Data Structures
Locks
Read/write (shared/exclusive) file locks are used to control concurrent access. LSM uses the following file-locks:
-
The DMS1 and DMS2 locking regions. These are used to implement the "dead-man-switch" mechanism copied from SQLite's WAL mode for safely connecting to and disconnecting from a database. See "Database Recovery and Shutdown" below.
-
Several (say 3) READER locking regions. Database clients hold a SHARED lock one of the READER locking regions while reading the database. As in SQLite WAL mode, each reader lock is paired with a value indicating the version of the database that the client process is using. The value consists of two fields:
- A 64-bit snapshot id. This identifies the version of the database file that the reader is accessing.
- A 32-bit shared-memory chunk id. This identifies the version of the in-memory tree the reader is reading.
-
The WRITER locking region. A database client holds an EXCLUSIVE lock on this locking region while writing data to the database. Outside of recovery, only clients holding this lock may modify the contents of the in-memory b-tree.
-
The WORKER lock. A database client holds an EXCLUSIVE lock on this locking region while writing data into the body of the database file.
-
The CHECKPOINTER lock. A database client holds an EXCLUSIVE lock on this locking region while writing to the database file header.
In the following sections, "the WRITER lock", refers to an exclusive lock on the WRITER locking region. For example "holding the WRITER lock" is equivalent to "holding an exclusive lock on the WRITER locking region". Similar interpretations apply to "the WORKER lock" and "the CHECKPOINTER lock".
Database file
This section summarizes the contents of the database file informally. A detailed description is found in the header comments for source code files lsm_file.c (blocks, pages etc.), lsm_sorted.c (sorted run format) and lsm_ckpt.c (database snapshot format).
The first 8KB of an LSM database file contains the database header. The database header is in turn divided into two 4KB "meta-pages". It is assumed that either of these two pages may be written without risking damage to the other in the event of a power failure. TODO: This assumption must be a problem. Do something about it.
The entire database file is divided into "blocks". The block-size is configurable (default 1MB). The first block includes the header, so contains less usable space than each subsequent block. Each block is sub-divided into configurably sized (default 4KB) pages. When reading from the database, clients read data into memory a page at a time (as they do when accessing SQLite's b-tree implementation). When writing to the database, the system attempts to write contiguously to an entire block before moving the disk head and writing elsewhere in the file.
As with an SQLite database file, each page in the database may be addressed by its 32-bit page number. This means the maximum database size is roughly (pgsz * 2^32) bytes. The first and last pages in each block are 4 bytes smaller than the others. This is to make room for a single page-number.
Sorted Runs
A single sorted run is spread across one or more database pages (each page is a part of at most one sorted run). Given the page number of a page in a sorted run the following statements are true:
- If the page is not the last page in the sorted run or the last page in a database file block, the next page in the same sorted run is the next page in the file. Or, if the page is the last page in a database file block, the next page is identified by the 4 byte page number stored as part of the last page on each block.
- If the page is not the first page in the sorted run or the first page in a database file block, the previous page in the same sorted run is the previous page in the file. Or, if the page is the first page in a database file block, the previous page is identified by the 4 byte page number stored as part of the first page on each block.
As well as pages containing user data, each sorted run contains "b-tree pages". These pages are similar to the internal nodes of b+-tree structures. They make it possible to treat the sorted-run as a b+tree when querying for a specific value or bounded range.
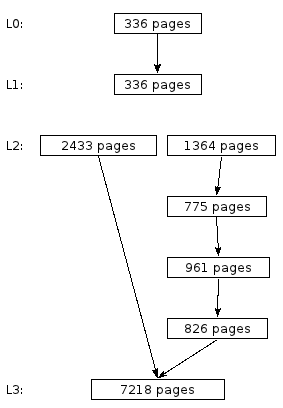
Figure 1.
In other words, given the page numbers of the first and last pages of a
sorted run and the page number of the root page for the embedded b-tree,
it is possible to traverse the entire run in either direction or query for
arbitrary values.
TODO: Embedded pointers.
Levels
Each sorted run is assigned to a "level". Normally, a level consists of a single sorted run. However, a level may also consist of a set of sorted runs being incrementally merged into a single run.
Figure 1 depicts a database that consists of 4 levels (L0, L1, L2 and L3). L3 contains the data most recently written to the database file. Each rectangular box in the diagram represents a single sorted run. Arrows represent embedded pointers. For example, the sorted run in L0 contains embedded pointers to the sorted run in L1.
Level L2 is an example of a level that consists of four sorted runs being merged into a single run. Once all the data in the runs to the right of the figure has been merged into the new run on the left hand side, the four original runs will be no longer required and the space they consume in the database file recycled. In the meantime, the system knows the value of the key most recently written to the left hand side. This key is known as the levels "split-key". When querying L2, if the key being queried for is less than or equal to the split-key, the left hand side of the level is searched. Otherwise, if the key being sought is larger than the split-key, the right hand side is searched.
Querying the database in figure 1 for a single key (K) therefore proceeds as follows:
-
A b+-tree search for the key is run on the sorted run in L0.
-
Use the embedded pointer (page number) located by the search of L0 to go directly to the page in the sorted run in L1 that may contain the key.
-
Since L2 is a split-level, compare K to the split-key. If K is less than or equal to the split-key, perform a b+-tree search of the sorted run on the left hand side of L2.
Otherwise, perform a b+-tree search of the 1364 page run on the right hand side of L2, then use the embedded pointers to search each subsequent run on the right hand side without accessing any b+-tree pages.
-
Regardless of whether the left or right side of L2 was searched, the search also locates a pointer to an L3 page. This pointer is used to load the page of the L3 sorted run that may contain K.
If, at any point in the search an instance of K is located, the remaining steps can be omitted and the results returned immediately. This means querying for recently written data may be significantly faster than the average query time for all entries.
Snapshots
Each meta page may contain a database snapshot. A snapshot contains all the information required to interpret the remainder of the database file (the sorted runs and free space). Specifically, it contains:
- A 64-bit checksum of the snapshot contents.
- A 64-bit snapshot id.
- The total number of blocks in the database file.
- The block size in bytes.
- The page size in bytes.
- A description of each of the levels in the database and the sorted runs they are made up of.
- A subset of the free-block list (see below).
- The log file offset (and initial checksum values) at which to begin log file recovery if this snapshot is loaded from disk (see "Database Recovery and Shutdown" below).
A more detailed description is available in the header comments in source code file lsm_ckpt.c
In-Memory Tree
The in-memory tree is an append-only b-tree of order 4 (each node may have up to 4 children), which is more or less equivalent to a red-black tree. An append-only tree is convenient, as it naturally supports the single-writer/many-readers MVCC concurrency model.
The implementation includes some optimizations to reduce the number of interior nodes that are updated when a leaf node is written that are not described here. See header comments in source code file lsm_tree.c for details.
Memory Allocation
More than one in-memory tree may exist in shared-memory at any time. For example in the following scenario:
- Reader process opens and starts reading in-memory tree.
- Writer process flushes the contents of the current in-memory tree to disk.
- Writer process begins inserting data into a second in-memory tree, while the reader process is still reading from the first.
In this case, the memory that was used for the first in-memory tree may not be reused until after the reader process has closed its read-transaction.
|
Rolling sequence ids It is conceivable that the 32-bit sequence ids assigned to shared memory chunks may overflow. However the approach described in this section assume that increasing sequence ids may be allocated indefinitely. This is reconciled using the following argument: Because of the way chunks are reused, it is not possible for chunk (I+1) to be recycled while there chunk I exists. The set of chunks that are present in shared memory always have a contiguous set of sequence ids. Therefore, assuming that there are not 2^30 or more chunks in shared-memory, it is possible to compare any two 32-bit unsigned sequence ids using the following: /* Return true if "a" is larger than or equal to "b" */ #define sequence_gt(a, b) (((u32)a-(u32)b) < (1<<30)) |
Within the shared memory region, space for the in-memory tree is allocated in 32KB chunks. Each time a new chunk is allocated from the end of the file, or an existing chunk reused, it is assigned a 32-bit monotonically increasing sequence value. This value is written to the first 4 bytes of the chunk. Additionally, all chunks are linked into a linked list in ascending order of sequence number using a 32-bit pointer value stored in the second 4-bytes of each chunk. The pointer to the first chunk in the list is stored in the tree-header (see below).
When a new 32KB chunk is required as part of inserting data into an append-only b-tree, LSM either reuses the first chunk in the linked list (if it is not part of the current in-memory tree or part of one that is still being used by a client), or else allocates a new chunk by extending the size of the shared-memory region.
If an application failure occurs while writing to the in-memory tree, the next writer detects that this has happened (see below). In this event, the sequence ids attached to shared-memory chunks are considered trustworthy, but the values that connect the linked list together are not. The writer that detects the failure must scan the entire shared-memory region to reconstruct the linked list. Any sequence ids assigned by the failed writer are reverted (perhaps not to their original values, but to values that put them at the start of the linked list - before those chunks that may still be in use by existing readers).
Header Fields
As well as the in-memory tree data, the following fixed-size fields stored in well-known locations in shared-memory are part of the in-memory tree. Like the in-memory tree data, outside of recovery these fields are only ever written to by clients holding the WRITER lock.
- Two copies of a data structure called a "tree-header". Tree-header-1 and tree-header 2. A tree-header structure contains all the information required to read or write to a particular version of the append only b-tree. It also contains a 64-bit checksum.
- A boolean flag set to true at the beginning of every write transaction and cleared after that transaction is successfully concluded - the "writer flag". This is used to detect failures that occur mid-transaction. It is only ever read (or written) by clients that hold the WRITER lock.
Other Shared-Memory Fields
- Snapshot 1.
- Snapshot 2.
- The meta-page pointer. This value is either 1 or 2. It indicates which of the two meta-pages contains the most recent database snapshot.
- READER lock values.
Log file
lsm_log.c.3. Database Recovery and Shutdown
Exclusive locks on locking region DMS1 are used to serialize all connect and disconnect operations.
When an LSM database connection is opened (i.e. lsm_open() is called):
lock(DMS1, EXCLUSIVE) # Block until successful
lock(DMS2, EXCLUSIVE) # Abandon if not immediately successful
if( DMS2 successfully locked ){
zero *-shm file (or equivalent)
run recovery
}
if( error during recovery ){
unlock(DMS2)
}else{
lock(DMS2, SHARED) # "cannot" fail
}
unlock(DMS1)
Running recovery involves reading the database file header and log file to initialize the contents of shared-memory. Recovery is only run when the first connection connects to the database file. There are no circumstances (including the unexpected failure of a writer process) that may cause recovery to take place after the first client has successfully connected.
Assuming recovery is successful (or not required), the database client is left holding a SHARED lock on DMS2. This lock is held for as long as the database connection remains open.
When disconnecting from a database (i.e. an lsm_close() call following a successful lsm_open()):
lock(DMS1, EXCLUSIVE) # Block until successful
lock(DMS2, EXCLUSIVE) # Abandon if not immediately successful
if( DMS2 successfully locked ){
...TODO...
delete *-shm file (or equivalent)
}
unlock(DMS2)
unlock(DMS1)
4. Database Operations
Reading
Opening a read transaction:
-
Load the current tree-header from shared-memory.
-
Load the current snapshot from shared-memory.
Steps 1 and 2 are similar. In both cases, there are two copies of the data structure being read in shared memory. No lock is held to prevent another client updating them while the read is taking place using the following pattern:
- Update copy 2.
- Invoke xShmBarrier().
- Update copy 1.
Because writers always use the pattern above, either copy 1 or copy 2 of the data structure being read should be valid at all times (i.e. not half-way through being updated). A valid read can be identified by checking that the 64-bit checksum embedded in both data structures matches the rest of the content. So steps 1 and 2 proceed as follows:
- Attempt to read copy 1 of the data structure.
- If step 1 is unsuccessful, attempt to read copy 2.
- If neither read attempt succeeded, invoke xShmBarrier() and re-attempt the operation.
- If the data structure cannot be read after a number of attempts, return the equivalent of SQLITE_PROTOCOL.
In the above, "attempting to read" a data structure means taking a private copy of the data and then attempting to verify its checksum. If the checksum matches the content of the tree-header or snapshot, then the attempted read is successful.
This is slightly different from the way SQLite WAL mode does things. SQLite also verifies that copy 1 and copy 2 of the data structure are identical. LSM could add an option to do that. However, to deal with the case where a writer/worker fails while updating one copy of the data structure, a reader would have to take the WRITER or WORKER lock as appropriate and "repair" the data structures so that both copies were consistent. See below under "Writing" and "Working" for details. This would mean we were only depending on the 64-bit checksums for recovery following an unluckily timed application failure, not for reader/writer collision detection.
-
Take a READER lock. The snapshot-id field of the reader-lock field must be less than or equal to the snapshot-id of the snapshot read in step 2. The shm-sequence-id of the reader lock must be less than or equal to the sequence-id of the first shared-memory chunk used by the in-memory tree according to the tree-header read in step 1.
-
Check that the tree-header read in step 1 is still current.
-
Check that the snapshot read in step 2 is still current.
Steps 5 and 6 are also similar. If the check in step 5 fails, there is a chance that the shared-memory chunks used to store the in-memory tree indicated by the tree-header read in step 1 had already been reused by a writer client before the lock in step 4 was obtained. And similarly if the check in step 6 fails, the database file blocks occupied by the sorted runs in the snapshot read in step 2 may have already been reused by new content. In either case, if the check fails, return to step 1 and start over.
Say a reader loads the tree-header for in-memory tree A, version 49 in step 1. Then, a writer writes a transaction to the in-memory tree A (creating version 50) and flushes the whole tree to disk, updating the current snapshot in shared-memory. All before the reader gets to step 2 above and loads the current snapshot. If allowed to proceed, the reader may return bad data or otherwise malfunction.
Step 4 should prevent this. If the above occurs, step 4 should detect that the tree-header loaded in step 1 is no longer current.
Once a read transaction is opened, the reader may continue to read the versions of the in-memory tree and database file for as long as the READER lock is held.
To close a read transaction all that is required is to drop the SHARED lock held on the READER slot.
Writing
To open a write transaction:
-
Open a read transaction, if one is not already open.
-
Obtain the WRITER lock.
-
Check if the "writer flag" is set. If so, repair the in-memory tree (see below).
-
Check that the tree-header loaded when the read transaction was opened matches the one currently stored in shared-memory to ensure this is not an attempt to write from an old snapshot.
-
Set the writer flag.
To commit a write transaction:
-
Update copy 2 of the tree-header.
-
Invoke xShmBarrier().
-
Update copy 1 of the tree-header.
-
Clear the transaction in progress flag.
-
Drop the WRITER lock.
Starting a new in-memory tree is similar executing a write transaction, except that as well as initializing the tree-header to reflect an empty tree, the snapshot id stored in the tree-header must be updated to correspond to the snapshot created by flushing the contents of the previous tree.
If the writer flag is set after the WRITER lock is obtained, the new writer assumes that the previous must have failed mid-transaction. In this case it performs the following:
- If the two tree-headers are not identical, copy one over the other. Prefer the data from a tree-header for which the checksum computes. Or, if they both compute, prefer tree-header-1.
- Sweep the shared-memory area to rebuild the linked list of chunks so that it is consistent with the current tree-header.
- Clear the writer flag.
Flushing the in-memory tree to disk
For the purposes of writing, the database file and the in-memory tree are largely independent. Processes holding the WRITER lock write to the in-memory tree, and processes holding the WORKER lock write to the database file.
- If a write transaction is open, write the new tree-header to shared-memory (as described above). Otherwise, if no write-transaction is open, open one - repairing the tree headers if required.
- Execute a WORKER transaction (see "Working" below) to add a new level to the LSM. The new level contains the current contents of the in-memory tree.
- Update the private copy of the tree-header to reflect a new, empty tree.
- Commit the write transaction, writing the new, empty tree to shared-memory.
Shared-memory management
A writer client may have to allocate new shared-memory chunks. This can be done either by extending the shared-memory region or by recycling the first chunk in the linked-list. To check if the first chunk in the linked-list may be reused, the writer must check that:
- The chunk is not part of the current in-memory tree (the one being appended to by the writer). A writer can check this by examining its private copy of the tree-header.
- The chunk is not part of an in-memory tree being used by an existing reader. A writer checks this by scanning (and possibly updating) the values associated with the READER locks - similar to the way SQLite does in WAL mode.
Log file management
A writer client also writes to the log file. All information required to write to the log file (the offset to write to and the initial checksum values) is embedded in the tree-header. Except, in order to reuse log file space (wrap around to the start of the log file), a writer needs to know that the space being recycled will not be required by any recovery process in the future. In other words, that the information contained in the transactions being overwritten has been written into the database file and is part of the snapshot written into the database file by a checkpointer (see "Checkpoint Operations" below).
To determine whether or not the log file can be wrapped, the writer requires access to information stored in the newest snapshot written into the database header. Their exists a shared-memory variable indicating which of the two meta-pages contain this snapshot, but the writer process still has to read the snapshot data and verify its checksum from disk.
Working
Working is similar to writing. The difference is that a "writer" modifies the in-memory tree. A "worker" modifies the contents of the database file.
-
Take the WORKER lock.
-
Check that the two snapshots in shared memory are identical. If not, and snapshot-1 has a valid checksum, copy snapshot-1 over the top of snapshot-2. Otherwise, copy snapshot-2 over the top of snapshot-1.
-
Modify the contents of the database file.
-
Update snapshot-2 in shared-memory.
-
Invoke xShmBarrier().
-
Update snapshot-1 in shared-memory.
-
Release the WORKER lock.
Free-block list management
Worker clients occasionally need to allocate new database blocks or move existing blocks to the free-block list. Along with the block number of each free block, the free-block list contains the snapshot-id of the first snapshot created after the block was moved to the free list. The free-block list is always stored in order of snapshot-id, so that the first block in the free list is the one that has been free for the longest.
There are two ways to allocate a new block - by extending the database file or by reusing a currently unused block from the head of the free-block list. There are two conditions for reusing a free-block:
- All existing database readers must be reading from snapshots with ids greater than or equal to the id stored in the free list. A worker process can check this by scanning the values associated with the READER locks - similar to the way SQLite does in WAL mode.
- The snapshot identified by the free-block list entry, or one with a more recent snapshot-id, must have been copied into the database file header. This is done by reading (and verifying the checksum) of the snapshot currently stored in the database meta-page indicated by the shared-memory variable.
Checkpoint Operations
- Take CHECKPOINTER lock.
- Load snapshot-1 from shared-memory. If the checksum does not match the content here, release the CHECKPOINTER lock and abandon the attempt to checkpoint the database.
- The shared-memory region contains a variable indicating the database meta-page that a snapshot was last read from or written to. Check if this page contains the same snapshot as just read from shared-memory.
- Sync the database file.
- Write the snapshot into a meta-page other than that (if any) currently identified by the shared-memory variable.
- Sync the database file again.
- Update the shared-memory variable to indicate the meta-page written in step 5.
- Drop the CHECKPOINTER lock.
5. Scheduling Policies
When a client writes to a database, the in-memory tree and log file are updated by the client itself before the lsm_write() call returns. Eventually, once sufficient writes have accumulated in memory, the client marks the current tree as "old", and subsequent writes are accumulated in a new tree.
In order to prevent the in-memory tree and log file from growing indefinitely, at some point in the future the following must occur:
- The contents of the old tree must be written into the database file (a WORKER lock operation). Once this is done the memory used to store the old tree is available for reuse.
- A checkpoint operation must take place to sync the data into the database file and update the database header (a CHECKPOINT lock operation). Once this has been done the log file space that was used to store the data may be reclaimed.
In addition to the above, it is necessary to perform a certain amount of work on the database to merge existing levels together. This is not just to speed up queries - there is a hard limit of roughly 40 levels to stop database snapshots from growing overly large.
Explicit Calls to lsm_work() and lsm_checkpoint()
Compulsory work
If a writer tries to mark a tree as "old", but there is already an old tree in-memory, the writer attempts to grab the WORKER lock and write both the old and new tree to a new database level.
If the WORKER lock cannot be obtained immediately, block until it can be
Auto work