Improving TCL Core Performance
Using Micro-optimizations
EuroTCL 2016 — Eindhoven
2016-06-26
CPU Cycles Used by SQLite
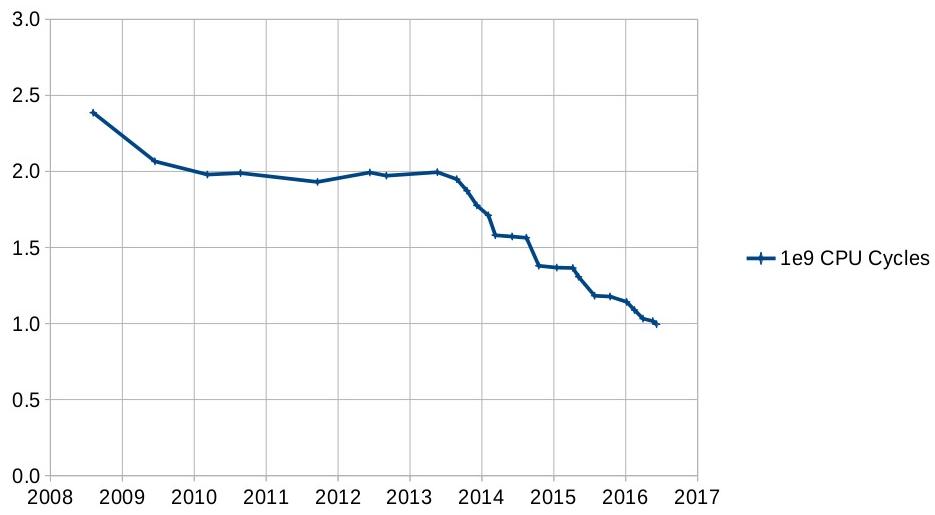
Ubuntu 14.04 x86_64, gcc 4.8.4, -Os
Can similiar optimizations be applied to TCL in order to double the speed of the interpreter?
Amalgation vs. Separate Files
| Build | CPU Cycles | Performance |
|---|---|---|
| Separate -Os | 1532.966911 | baseline |
| Separate -O6 | 1522.189222 | -0.7% |
| Amalgamation -Os | 1459.618198 | -4.8% |
| Amalgamation -O6 | 1430.548506 | -6.7% |
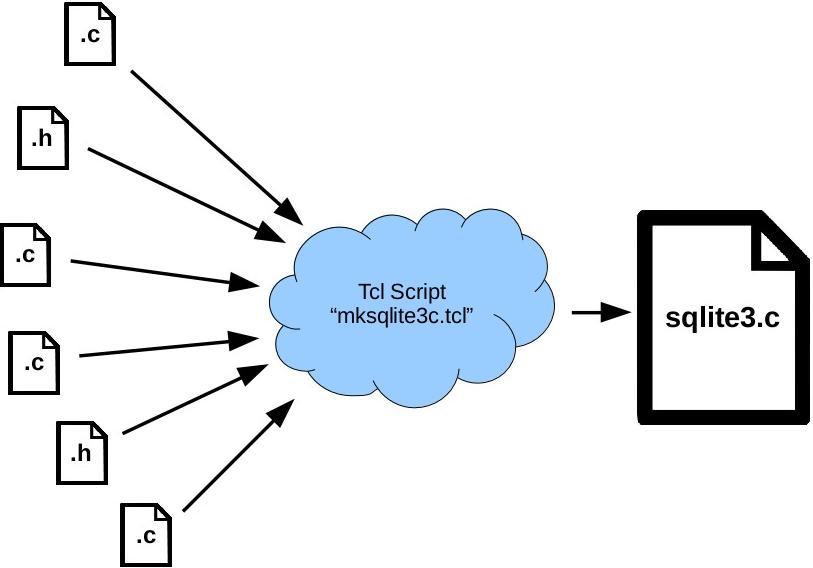
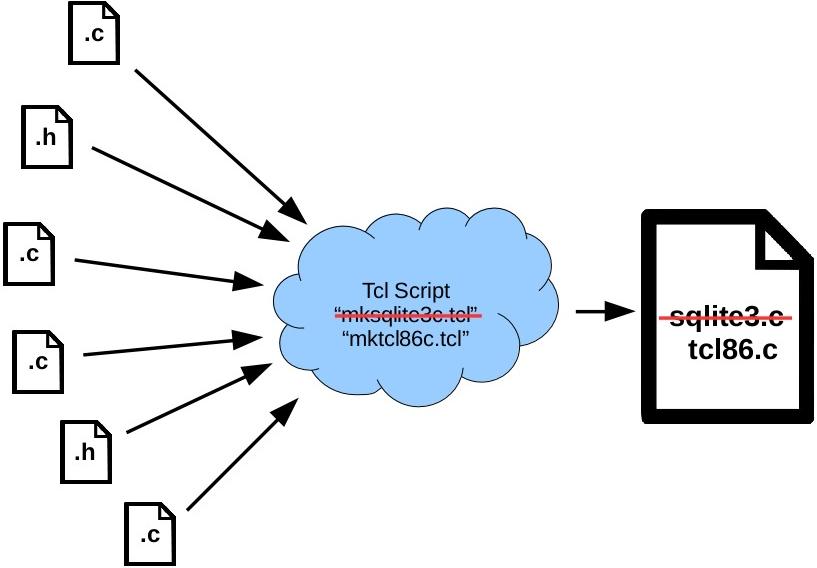
Amalgamation Advantages
- Runs faster
- Compiler optimizations are more effective
- Easier to integrate into another project
Tools You Will Need
- A high-quality test suite
- A deterministic TCL script that represents a "typical" workload
- No threads
- No [eval {rand()}]
- Linux workstations with lots of pixels
- valgrind/cachegrind installed
lcamtuf.coredump.cx/afl/
Algorithm
- Run the workload script using cachegrind
- Study cachegrind output to find microoptimizations
- Make code changes
- Test, test, test....
- Goto 1
Running The Workload
rm -f cachegrind.out.* make clean tclsh valgrind --tool=cachegrind ./tclsh workload.tcl cg_anno.tcl cachegrind.out.* >cout-current.txt fossil test-diff --tk cout-baseline.tcl cout-current.txt &
cg_anno.tcl
#!/usr/bin/tclsh
set in [open "|cg_annotate --show=Ir --auto=yes $argv" r]
set dest !
set out(!) {}
while {![eof $in]} {
set line [gets $in]
set line [string map {\t { }} [gets $in]]
if {[regexp {^-- Auto-annotated source: (.*)} $line all nm]} {
set dest $nm
} elseif {[regexp {^-- line \d+ ------} $line]} {
set line [lreplace $line 2 2 {#}]
} elseif {[regexp {^The following files chosen for } $line]} {
set dest !
}
append out($dest) $line\n
}
foreach x [lsort [array names out]] {
puts $out($x)
}
https://www.sqlite.org/src/info/618d8dd4ff4
514,274 const int bMmapOk = (pgno!=1 && USEFETCH(pPager)
771,867 && (pPager->eState==PAGER_READER || (flags & PAGER_GE
. );
514,274 if( pgno==0 ){
. return SQLITE_CORRUPT_BKPT;
. }
Before ↑ After ↓
514,274 const int bMmapOk = (pgno>1 && USEFETCH(pPager)
514,578 && (pPager->eState==PAGER_READER || (flags & PAGER_GE
. );
304 if( pgno<=1 && pgno==0 ){
257,289 return SQLITE_CORRUPT_BKPT;
. }
Saved 513K cycles out of 675M = 0.07%
Demo Workload
# Speed test workload demo #1
#
set res {}
for {set j 0} {$j<1000} {incr j} {
set a0 1
set a1 1
for {set i 0} {$i<30} {incr i} {
set x [expr {$a0+$a1}]
set a0 $a1
set a1 $x
append res " $x"
}
}
puts $res
Cachegrind Output
262,402,580 PROGRAM TOTALS -------------------------------------------------------------- 49,838,612 /tmp/generic/tclExecute.c:TEBCresume 32,018,100 /tmp/generic/tclNamesp.c:TclGetNamespaceForQualNam 26,221,282 /tmp/generic/tclVar.c:TclObjLookupVarEx 24,875,355 /tmp/generic/tclVar.c:ObjFindNamespaceVar 24,844,452 /tmp/generic/tclHash.c:CreateHashEntry 21,851,978 /tmp/generic/tclVar.c:TclLookupSimpleVar 8,220,562 /tmp/generic/tclObj.c:TclHashObjKey 7,623,937 /tmp/generic/tclVar.c:TclPtrSetVar 6,500,844 /tmp/generic/tclVar.c:CompareVarKeys 6,169,552 pthread_getspecific.c:pthread_getspecific 5,403,119 /tmp/generic/tclUtil.c:Tcl_DStringFree 4,369,586 /tmp/generic/tclVar.c:FreeParsedVarName 3,741,590 /tmp/generic/tclThreadAlloc.c:TclpAlloc 3,682,721 /tmp/generic/tclEncoding.c:UtfToUtfProc.isra.0
. static int CompareVarKeys(
. void *keyPtr,
. Tcl_HashEntry *hPtr)
2,016,738 {
. Tcl_Obj *objPtr1 = keyPtr;
336,123 Tcl_Obj *objPtr2 = hPtr->key.objPtr;
. register const char *p1, *p2;
. register int l1, l2;
672,246 if (objPtr1 == objPtr2) {
672,246 return 1;
. }
90,126 p1 = TclGetString(objPtr1);
30,042 l1 = objPtr1->length;
90,126 p2 = TclGetString(objPtr2);
. l2 = objPtr2->length;
240,336 return ((l1 == l2) && !memcmp(p1, p2, l1));
2,352,861 }
CPU Registers
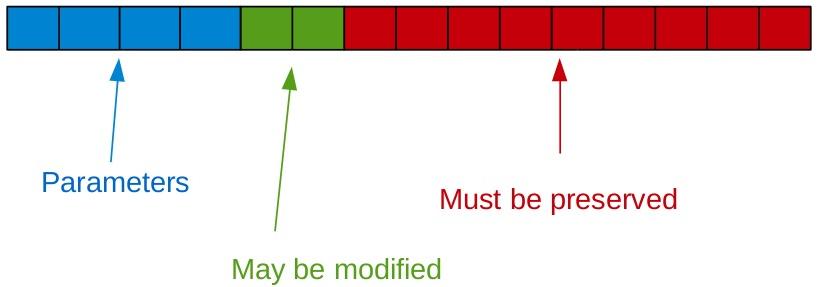
Registers must push to stack if...
- Many registers needed — complex function
- Subroutines called, except tail recursion
. static int CompareVarKeys(
. void *keyPtr,
. Tcl_HashEntry *hPtr)
. {
. Tcl_Obj *objPtr1 = keyPtr;
336,123 Tcl_Obj *objPtr2 = hPtr->key.objPtr;
672,246 if (objPtr1 == objPtr2) {
. return 1;
. } else {
30,042 return CompareDtnctVarKeys(objPtr1, objPtr2);
. }
612,162 }
. static TCL_NOINLINE int CompareDtnctVarKeys(
. Tcl_Obj *objPtr1,
. Tcl_Obj *objPtr2)
150,210 {
90,126 const char *p1 = TclGetString(objPtr1);
30,042 int l1 = objPtr1->length;
90,126 const char *p2 = TclGetString(objPtr2);
. int l2 = objPtr2->length;
270,378 return ((l1 == l2) && !memcmp(p1, p2, l1));
120,168 }
TCL_NOINLINE
#if defined(__GNUC__) # define TCL_NOINLINE __attribute__((noinline)) #elif defined(_MSC_VER) && _MSC_VER>=1310 # define TCL_NOINLINE __declspec(noinline) #else # define TCL_NOINLINE #endif
Currently on branch mig-opt2. Not yet on trunk
End Result
- Saved about 4M cycles out of 262M → 1.5% faster!
- This change is not checked in because Miguel found a better way to fix the frequent calls to CompareVarKeys()
2,021,099,349 PROGRAM TOTALS ----------------------------------------------------- 390,649,348 /tmp/generic/tclExecute.c:TEBCresume 150,647,394 ???:pthread_getspecific 123,209,668 /tmp/generic/tclHash.c:CreateHashEntry 118,133,666 /tmp/generic/tclObj.c:TclHashObjKey 74,396,324 /tmp/generic/tclVar.c:UnsetVarStruct 73,162,765 /tmp/generic/tclThreadAlloc.c:TclpAlloc 56,342,657 /tmp/generic/tclThreadAlloc.c:TclpFree
. void *
. TclpGetAllocCache(void)
1 {
17,368,092 if (!initialized) {
2 pthread_mutex_lock(allocLockPtr);
3 if (!initialized) {
3 pthread_key_create(&key,TclpFreeAllocCache);
1 initialized = 1;
. }
2 pthread_mutex_unlock(allocLockPtr);
. }
11,578,728 return pthread_getspecific(key);
2 }
Check-in [fdbf64dc50]
. void *
. TclpGetAllocCache(void)
. {
11,578,728 return pthread_getspecific(key);
. }
Saved 17.3M out of 2021M cycles → 0.99% faster
Takeaways
- CPUs have stopped getting faster — future performance gains must come from code optimization
- TCL is ripe for micro-optimization
- Use cachegrind for repeatable measurements
- Many 0.1% improvements add up over time
- Doubling the speed of TCL is possible